¿Qué tan lenta es la concatenación de cadenas de Python frente a str.join?
Como resultado de los comentarios en mi respuesta en este hilo , quería saber cuál es la diferencia de velocidad entre el +=operador y''.join()
Entonces, ¿cuál es la comparación de velocidad entre los dos?
De: Concatenación de cadenas eficiente
Método 1:
def method1():
out_str = ''
for num in xrange(loop_count):
out_str += 'num'
return out_str
Método 4:
def method4():
str_list = []
for num in xrange(loop_count):
str_list.append('num')
return ''.join(str_list)
Ahora me doy cuenta de que no son estrictamente representativos, y el cuarto método se agrega a una lista antes de recorrer y unir cada elemento, pero es una indicación justa.
La unión de cadenas es significativamente más rápida que la concatenación.
¿Por qué? Las cadenas son inmutables y no se pueden cambiar en su lugar. Para modificar uno, es necesario crear una nueva representación (una concatenación de las dos).
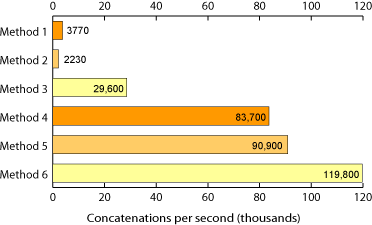
Nota: Este punto de referencia fue informal y debe rehacerse porque no muestra una imagen completa de cómo funcionarán estos métodos con cadenas más largas de manera más realista. Como se menciona en los comentarios de @Mark Amery, no+= es tan rápido como usar cadenas y no es tan dramáticamente más lento en casos de uso realistas.fstr#join
Es probable que estas métricas también estén desactualizadas debido a las importantes mejoras de rendimiento introducidas por las versiones posteriores de CPython y, más notablemente, la 3.11.
Las respuestas existentes están muy bien escritas e investigadas, pero aquí hay otra respuesta para la era Python 3.6, ya que ahora tenemos interpolación de cadenas literal (también conocida como f-strings):
>>> import timeit
>>> timeit.timeit('f\'{"a"}{"b"}{"c"}\'', number=1000000)
0.14618930302094668
>>> timeit.timeit('"".join(["a", "b", "c"])', number=1000000)
0.23334730707574636
>>> timeit.timeit('a = "a"; a += "b"; a += "c"', number=1000000)
0.14985873899422586
Prueba realizada con CPython 3.6.5 en una Retina MacBook Pro 2012 con Intel Core i7 a 2,3 GHz.
Mi código original era incorrecto, parece que +la concatenación suele ser más rápida (especialmente con versiones más nuevas de Python en hardware más nuevo)
Los tiempos son los siguientes:
Iterations: 1,000,000
Python 3.3 en Windows 7, Core i7
String of len: 1 took: 0.5710 0.2880 seconds
String of len: 4 took: 0.9480 0.5830 seconds
String of len: 6 took: 1.2770 0.8130 seconds
String of len: 12 took: 2.0610 1.5930 seconds
String of len: 80 took: 10.5140 37.8590 seconds
String of len: 222 took: 27.3400 134.7440 seconds
String of len: 443 took: 52.9640 170.6440 seconds
Python 2.7 en Windows 7, Core i7
String of len: 1 took: 0.7190 0.4960 seconds
String of len: 4 took: 1.0660 0.6920 seconds
String of len: 6 took: 1.3300 0.8560 seconds
String of len: 12 took: 1.9980 1.5330 seconds
String of len: 80 took: 9.0520 25.7190 seconds
String of len: 222 took: 23.1620 71.3620 seconds
String of len: 443 took: 44.3620 117.1510 seconds
En Linux Mint, Python 2.7, algún procesador más lento
String of len: 1 took: 1.8840 1.2990 seconds
String of len: 4 took: 2.8394 1.9663 seconds
String of len: 6 took: 3.5177 2.4162 seconds
String of len: 12 took: 5.5456 4.1695 seconds
String of len: 80 took: 27.8813 19.2180 seconds
String of len: 222 took: 69.5679 55.7790 seconds
String of len: 443 took: 135.6101 153.8212 seconds
Y aquí está el código:
from __future__ import print_function
import time
def strcat(string):
newstr = ''
for char in string:
newstr += char
return newstr
def listcat(string):
chars = []
for char in string:
chars.append(char)
return ''.join(chars)
def test(fn, times, *args):
start = time.time()
for x in range(times):
fn(*args)
return "{:>10.4f}".format(time.time() - start)
def testall():
strings = ['a', 'long', 'longer', 'a bit longer',
'''adjkrsn widn fskejwoskemwkoskdfisdfasdfjiz oijewf sdkjjka dsf sdk siasjk dfwijs''',
'''this is a really long string that's so long
it had to be triple quoted and contains lots of
superflous characters for kicks and gigles
@!#(*_#)(*$(*!#@&)(*E\xc4\x32\xff\x92\x23\xDF\xDFk^%#$!)%#^(*#''',
'''I needed another long string but this one won't have any new lines or crazy characters in it, I'm just going to type normal characters that I would usually write blah blah blah blah this is some more text hey cool what's crazy is that it looks that the str += is really close to the O(n^2) worst case performance, but it looks more like the other method increases in a perhaps linear scale? I don't know but I think this is enough text I hope.''']
for string in strings:
print("String of len:", len(string), "took:", test(listcat, 1000000, string), test(strcat, 1000000, string), "seconds")
testall()
Si lo espero bien, para una lista con k cadenas, con n caracteres en total, la complejidad temporal de la unión debería ser O(nlogk), mientras que la complejidad temporal de la concatenación clásica debería ser O(nk).
Serían los mismos costos relativos que fusionar k listas ordenadas (el método eficiente es O(nlkg), mientras que el simple, similar a la concatenación, es O(nk) ).