¿Es posible hacer una clave externa de MySQL para una de dos tablas posibles?
Bueno aquí está mi problema tengo tres mesas; regiones, países, estados. Los países pueden estar dentro de regiones, los estados pueden estar dentro de regiones. Las regiones son la cima de la cadena alimentaria.
Ahora estoy agregando una tabla de áreas_populares con dos columnas; id_región y id_lugar_popular. ¿Es posible hacer que popular_place_id sea una clave externa para países O estados? Probablemente tendré que agregar una columna popular_place_type para determinar si la identificación describe un país o estado de cualquier manera.
Lo que estás describiendo se llama Asociaciones Polimórficas. Es decir, la columna "clave externa" contiene un valor de identificación que debe existir en una de un conjunto de tablas de destino. Normalmente, las tablas de destino están relacionadas de alguna manera, como ser instancias de alguna superclase de datos común. También necesitaría otra columna junto a la columna de clave externa, de modo que en cada fila pueda designar a qué tabla de destino se hace referencia.
CREATE TABLE popular_places (
user_id INT NOT NULL,
place_id INT NOT NULL,
place_type VARCHAR(10) -- either 'states' or 'countries'
-- foreign key is not possible
);
No hay forma de modelar asociaciones polimórficas utilizando restricciones SQL. Una restricción de clave externa siempre hace referencia a una tabla de destino.
Las asociaciones polimórficas están respaldadas por marcos como Rails e Hibernate. Pero dicen explícitamente que debes deshabilitar las restricciones de SQL para usar esta función. En cambio, la aplicación o marco debe realizar un trabajo equivalente para garantizar que se cumpla la referencia. Es decir, el valor de la clave externa está presente en una de las posibles tablas de destino.
Las asociaciones polimórficas son débiles con respecto a hacer cumplir la coherencia de la base de datos. La integridad de los datos depende de que todos los clientes accedan a la base de datos con la misma lógica de integridad referencial aplicada, y además la aplicación debe estar libre de errores.
A continuación se muestran algunas soluciones alternativas que aprovechan la integridad referencial impuesta por la base de datos:
Cree una tabla adicional por objetivo. Por ejemplo popular_statesy popular_countries, que hacen referencia statesa y countriesrespectivamente. Cada una de estas tablas "populares" también hace referencia al perfil del usuario.
CREATE TABLE popular_states (
state_id INT NOT NULL,
user_id INT NOT NULL,
PRIMARY KEY(state_id, user_id),
FOREIGN KEY (state_id) REFERENCES states(state_id),
FOREIGN KEY (user_id) REFERENCES users(user_id),
);
CREATE TABLE popular_countries (
country_id INT NOT NULL,
user_id INT NOT NULL,
PRIMARY KEY(country_id, user_id),
FOREIGN KEY (country_id) REFERENCES countries(country_id),
FOREIGN KEY (user_id) REFERENCES users(user_id),
);
Esto significa que para obtener todos los lugares favoritos de un usuario es necesario consultar ambas tablas. Pero significa que puede confiar en la base de datos para imponer la coherencia.
Crea una placestabla como supertabla. Como menciona Abie, una segunda alternativa es que sus lugares populares hagan referencia a una tabla como places, que es padre de ambos statesy countries. Es decir, tanto los estados como los países también tienen una clave externa para places(incluso puedes hacer que esta clave externa también sea la clave principal de statesy countries).
CREATE TABLE popular_areas (
user_id INT NOT NULL,
place_id INT NOT NULL,
PRIMARY KEY (user_id, place_id),
FOREIGN KEY (place_id) REFERENCES places(place_id)
);
CREATE TABLE states (
state_id INT NOT NULL PRIMARY KEY,
FOREIGN KEY (state_id) REFERENCES places(place_id)
);
CREATE TABLE countries (
country_id INT NOT NULL PRIMARY KEY,
FOREIGN KEY (country_id) REFERENCES places(place_id)
);
Utilice dos columnas. En lugar de una columna que pueda hacer referencia a cualquiera de las dos tablas de destino, utilice dos columnas. Estas dos columnas pueden ser NULL; de hecho, sólo uno de ellos debería ser no NULL.
CREATE TABLE popular_areas (
place_id SERIAL PRIMARY KEY,
user_id INT NOT NULL,
state_id INT,
country_id INT,
CONSTRAINT UNIQUE (user_id, state_id, country_id), -- UNIQUE permits NULLs
CONSTRAINT CHECK (state_id IS NOT NULL OR country_id IS NOT NULL),
FOREIGN KEY (state_id) REFERENCES places(place_id),
FOREIGN KEY (country_id) REFERENCES places(place_id)
);
En términos de teoría relacional, las Asociaciones Polimórficas violan la Primera Forma Normal , porque popular_place_iden realidad es una columna con dos significados: es un estado o un país. No almacenarías el de una persona agey el suyo phone_numberen una sola columna y, por la misma razón, no deberías almacenar ambos state_iden country_iduna sola columna. El hecho de que estos dos atributos tengan tipos de datos compatibles es una coincidencia; todavía significan diferentes entidades lógicas.
Las asociaciones polimórficas también violan la tercera forma normal , porque el significado de la columna depende de la columna adicional que nombra la tabla a la que se refiere la clave externa. En la tercera forma normal, un atributo de una tabla debe depender únicamente de la clave principal de esa tabla.
Re comentario de @SavasVedova:
No estoy seguro de seguir su descripción sin ver las definiciones de las tablas o una consulta de ejemplo, pero parece que simplemente tiene varias Filterstablas, cada una de las cuales contiene una clave externa que hace referencia a una Productstabla central.
CREATE TABLE Products (
product_id INT PRIMARY KEY
);
CREATE TABLE FiltersType1 (
filter_id INT PRIMARY KEY,
product_id INT NOT NULL,
FOREIGN KEY (product_id) REFERENCES Products(product_id)
);
CREATE TABLE FiltersType2 (
filter_id INT PRIMARY KEY,
product_id INT NOT NULL,
FOREIGN KEY (product_id) REFERENCES Products(product_id)
);
...and other filter tables...
Unir los productos a un tipo de filtro específico es fácil si sabes a qué tipo quieres unirte:
SELECT * FROM Products
INNER JOIN FiltersType2 USING (product_id)
Si desea que el tipo de filtro sea dinámico, debe escribir código de aplicación para construir la consulta SQL. SQL requiere que la tabla se especifique y corrija en el momento de escribir la consulta. No puede hacer que la tabla unida se elija dinámicamente en función de los valores encontrados en filas individuales de Products.
La única otra opción es unirse a todas las tablas de filtro mediante combinaciones externas. Aquellos que no tengan ningún product_id coincidente simplemente se devolverán como una sola fila de valores nulos. Pero aún debe codificar todas las tablas unidas y, si agrega nuevas tablas de filtro, debe actualizar su código.
SELECT * FROM Products
LEFT OUTER JOIN FiltersType1 USING (product_id)
LEFT OUTER JOIN FiltersType2 USING (product_id)
LEFT OUTER JOIN FiltersType3 USING (product_id)
...
Otra forma de unirse a todas las tablas de filtros es hacerlo en serie:
SELECT * FROM Product
INNER JOIN FiltersType1 USING (product_id)
UNION ALL
SELECT * FROM Products
INNER JOIN FiltersType2 USING (product_id)
UNION ALL
SELECT * FROM Products
INNER JOIN FiltersType3 USING (product_id)
...
Pero este formato aún requiere que escribas referencias a todas las tablas. No hay forma de evitar eso.
Esta no es la solución más elegante del mundo, pero podría utilizar la herencia de tablas concretas para que esto funcione.
Conceptualmente usted está proponiendo una noción de una clase de "cosas que pueden ser áreas populares" de la cual heredan sus tres tipos de lugares. Podría representar esto como una tabla llamada, por ejemplo, placesdonde cada fila tiene una relación uno a uno con una fila en regions, countrieso states. (Los atributos que se comparten entre regiones, países o estados, si los hay, podrían insertarse en esta tabla de lugares). Su popular_place_idsería entonces una referencia de clave externa a una fila en la tabla de lugares que luego lo llevaría a una región, país , o estado.
La solución que propone con una segunda columna para describir el tipo de asociación es cómo Rails maneja las asociaciones polimórficas, pero no soy un fanático de eso en general. Bill explica con excelente detalle por qué las asociaciones polimórficas no son tus amigas.
Aquí hay una corrección al enfoque de "supertabla" de Bill Karwin, utilizando una clave compuesta ( place_type, place_id )para resolver las violaciones de forma normal percibidas:
CREATE TABLE places (
place_id INT NOT NULL UNIQUE,
place_type VARCHAR(10) NOT NULL
CHECK ( place_type = 'state', 'country' ),
UNIQUE ( place_type, place_id )
);
CREATE TABLE states (
place_id INT NOT NULL UNIQUE,
place_type VARCHAR(10) DEFAULT 'state' NOT NULL
CHECK ( place_type = 'state' ),
FOREIGN KEY ( place_type, place_id )
REFERENCES places ( place_type, place_id )
-- attributes specific to states go here
);
CREATE TABLE countries (
place_id INT NOT NULL UNIQUE,
place_type VARCHAR(10) DEFAULT 'country' NOT NULL
CHECK ( place_type = 'country' ),
FOREIGN KEY ( place_type, place_id )
REFERENCES places ( place_type, place_id )
-- attributes specific to country go here
);
CREATE TABLE popular_areas (
user_id INT NOT NULL,
place_id INT NOT NULL,
UNIQUE ( user_id, place_id ),
FOREIGN KEY ( place_type, place_id )
REFERENCES places ( place_type, place_id )
);
Lo que este diseño no puede garantizar es que por cada fila placesexista una fila stateso countries(pero no ambas). Esta es una limitación de las claves externas en SQL. En un DBMS que cumpla completamente con los estándares SQL-92, podría definir restricciones entre tablas diferibles que le permitirían lograr lo mismo, pero es complicado, implica transacciones y dicho DBMS aún no ha llegado al mercado.
Respuesta relacional
Observando la mysqletiqueta, lo que implica relational, porque SQL es el sublenguaje de datos definido en el Modelo Relacional de Codd .
- La solución es simple y directa, la teníamos antes de RM y tenemos una solución relacional desde 1981.
- La solución Relacional proporciona tanto Integridad Referencial (física, a nivel SQL) como Integridad Relacional (lógica).
- Cumplir con los Estándares de Arquitectura Abierta (cordura), todas las Restricciones; reglas del negocio; etc. que gobiernan los datos, así como todas las transacciones, deben implementarse en la base de datos, no en el marco, ni en la GUI de la aplicación, ni en el nivel medio de la aplicación. Tenga en cuenta que es una única unidad de recuperación.
La polymorphic-associationsetiqueta es falsa, OP no la solicitó. Forzarlo a adoptar una mentalidad OO/ORM y luego demostrar una solución con esa mentalidad está fuera del alcance de la pregunta.
- Además, requiere un marco y un código para imponer restricciones; etc, fuera de la base de datos, que no cumple con los estándares.
- Además, no tiene la integridad básica, y mucho menos la integridad relacional, de la solución relacional.
- Además, viola
1NFy3NF(como se detalla en la Respuesta de Karvan). - Los valores nulos son un error de normalización y nunca deben almacenarse.
- Un valor anulable
FOREIGN KEYes un grave error de normalización.
Solución
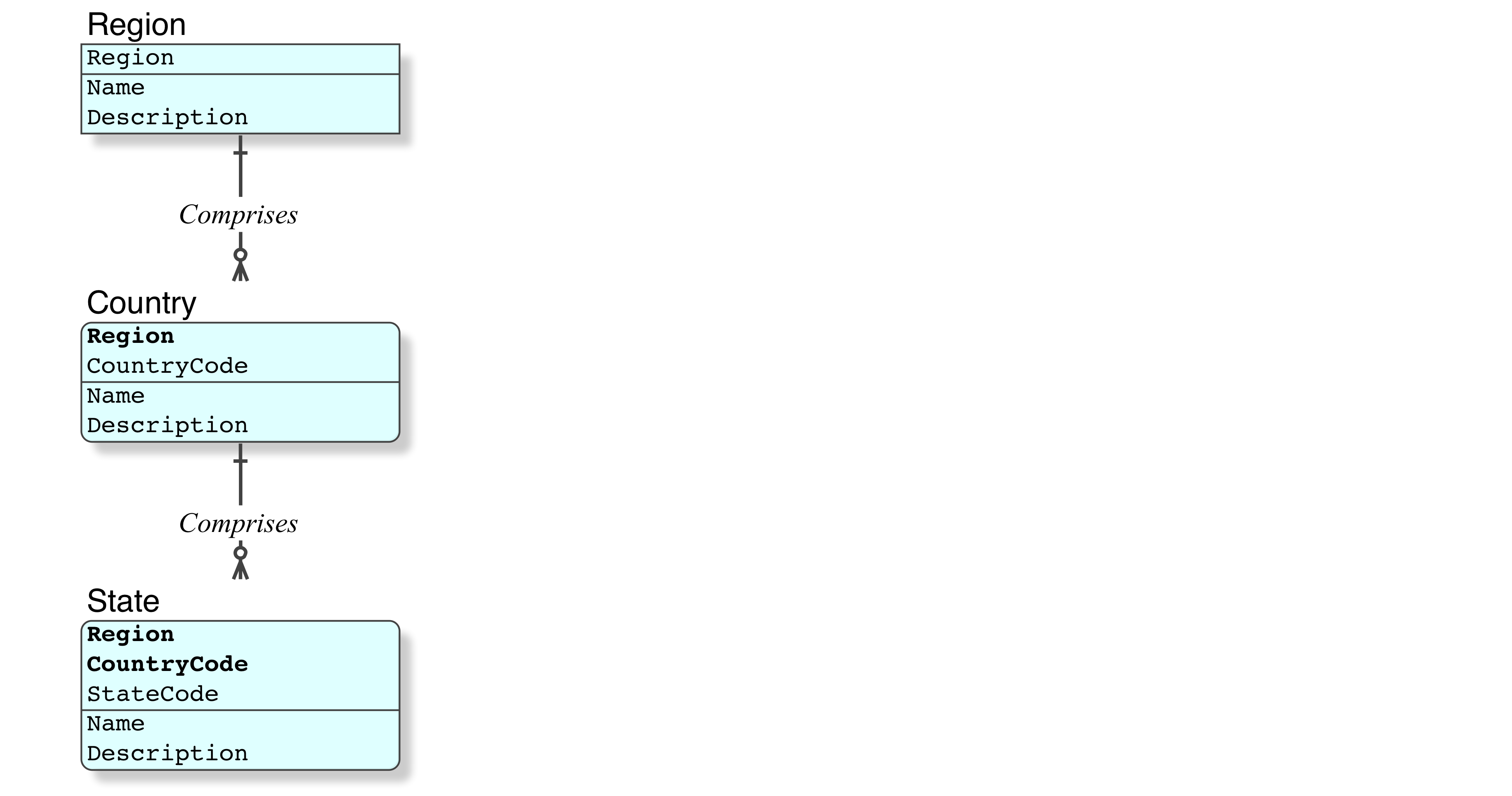
Bueno aquí está mi problema tengo tres mesas; regiones, países, estados. Los países pueden estar dentro de regiones, los estados pueden estar dentro de regiones. Las regiones son la cima de la cadena alimentaria.
Hazlo relacional
Entendamos qué es eso en el contexto relacional. Es una jerarquía típica de tablas.
- No utilice
IDcampos. No los declares comoPRIMARY KEY, eso sólo te confundirá, porque no es una clave, no proporciona unicidad de fila como lo exige el modelo relacional. - Se debe crear una clave a partir de los datos.
- Un
IDcampo no son datos. Siempre es un campo adicional y un índice adicional . - Con
IDlos campos, es posible que pueda implementar la integridad referencial (física, SQL), pero no tiene ninguna posibilidad de implementar la integridad relacional (lógica) - Para una discusión completa, incluido el código SQL, consulte:
Creación de una tabla relacional con 2 auto_increment diferentes , §1 y 2 únicamente.
Mesas Base
Notación
Todos mis modelos de datos se representan en IDEF1X , la notación para el modelado de datos relacionales, que hemos tenido desde principios de la década de 1980, que se convirtió en el Estándar para el modelado de datos relacionales en 1993 y se actualizó por última vez en 2016.
La Introducción a IDEF1X es una lectura esencial para aquellos que son nuevos en el Modelo Relacional o su método de modelado. Tenga en cuenta que los modelos IDEF1X son ricos en detalles y precisión y muestran todos los detalles requeridos, mientras que un modelo interno, al desconocer los imperativos del estándar, tiene mucha menos definición. Lo que significa que es necesario comprender completamente la notación.
ERD no es un estándar, no admite el modelo relacional y es completamente inadecuado para el modelado.
Que los académicos y los "libros de texto" enseñen y comercialicen lo anti-relacional como "relacional" es criminal.
Subtipo
Ahora estoy agregando una tabla de áreas_populares con dos columnas; id_región y id_lugar_popular. ¿Es posible hacer que popular_place_id sea una clave externa para países O estados?
No hay problema. El Modelo Relacional se fundamenta en las Matemáticas; Lógica, es completamente lógica. Una puerta OR o XOR es un fundamento de la lógica. En el paradigma relacional o SQL, se denomina clúster de subtipo .
Incluso en los "SQL" gratuitos, que no son compatibles con SQL, se realiza con total integridad referencial.
- la idea de que no se puede hacer, o que requiere los horrendos campos e índices adicionales comercializados por los académicos, es falsa.
Para obtener detalles completos de la implementación, incluidos enlaces al código SQL, consulte el documento Subtipo .
Para ejemplos y discusión, consulte:
Cómo implementar la integridad referencial en subtiposPara aclarar cuestiones que confunden esta pregunta y, por lo tanto, las otras respuestas:
esquema relacional para un gráfico de libro
Probablemente tendré que agregar una columna popular_place_type para determinar si la identificación describe un país o estado de cualquier manera.
Correcto, estás pensando con lógica. Aquí necesitamos una puerta XOR , que requiere un discriminador .
Agregar tabla de lugar
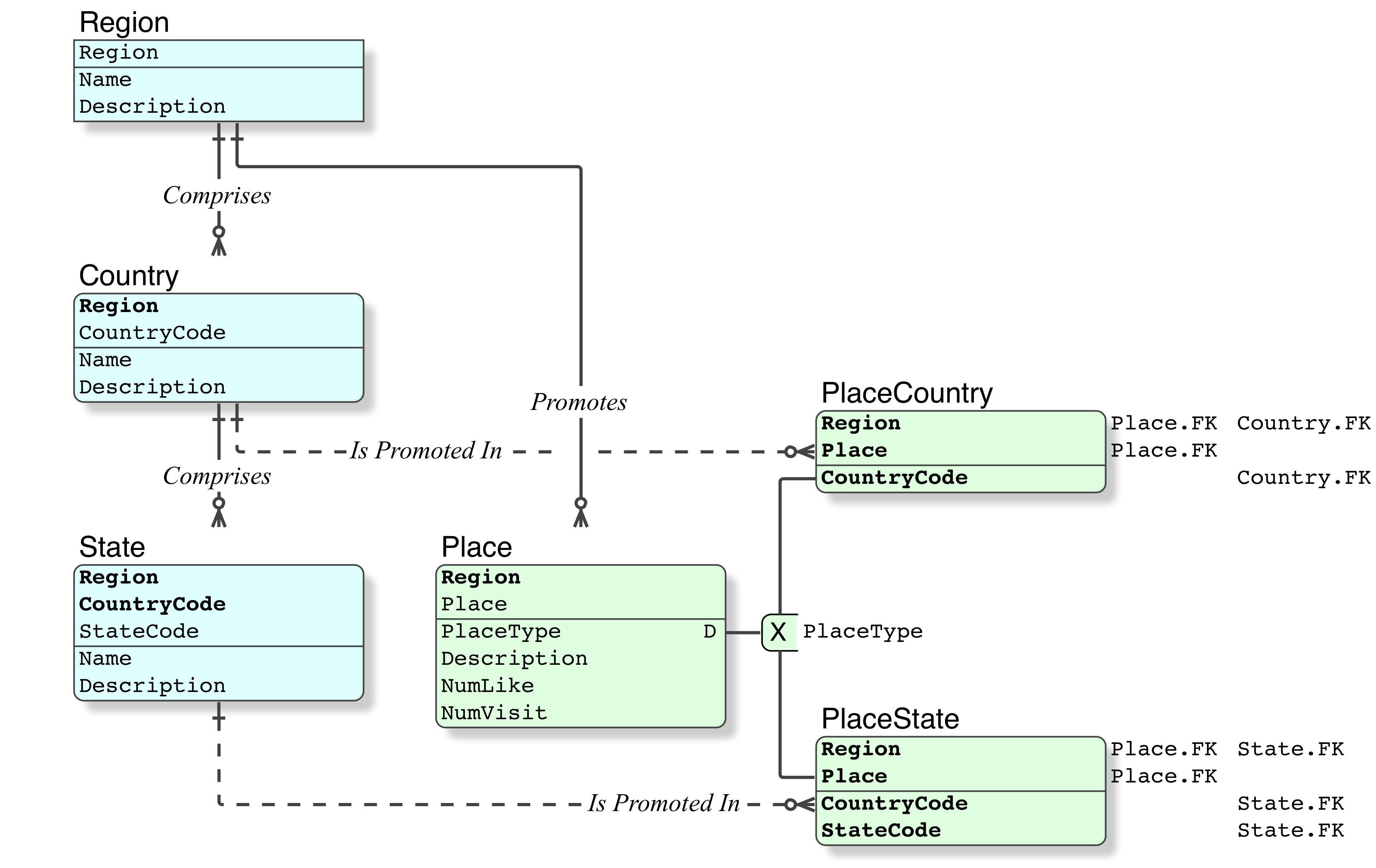
Integridad relacional
Mientras que la integridad referencial es la característica física proporcionada en SQL, la integridad relacional, que es lógica, está por encima de eso (cuando se modela correctamente, lo lógico precede a lo físico).
Este es un gran y sencillo ejemplo de integridad relacional. Tenga en cuenta el segundo FOREIGN KEYen los Subtipos.
PlaceCountryestá restringido a aCountryque es igualRegionquePlace.RegionPlaceStateestá restringido a aStateque es igualRegionquePlace.RegionTenga en cuenta que esto sólo es posible con claves relacionales (compuestas)
- La integridad relacional no es posible en los primitivos sistemas de archivo de registros, que se caracterizan por
IDcampos como "claves" y que los académicos y autores comercializan en gran medida como "relacionales". - En archivos tan primitivos (no son tablas),
PlaceCountryse permitiría anyCountry, no se puede restringir a unoCountryque sea igualRegionquePlace.Region.
- La integridad relacional no es posible en los primitivos sistemas de archivo de registros, que se caracterizan por